什么是RLHF?
**字面翻译:**RLHF (Reinforcement Learning from Human Feedback) ,即以强化学习方式依据人类反馈优化语言模型。
强化学习从人类反馈(RLHF)是一种先进的AI系统训练方法,它将强化学习与人类反馈相结合。它是一种通过将人类训练师的智慧和经验纳入模型训练过程中,创建更健壮的学习过程的方法。该技术涉及使用人类反馈创建奖励信号,然后通过强化学习来改善模型的行为。
强化学习,简单来说,是一个过程,其中AI代理通过与环境的交互和以奖励或惩罚的形式获得的反馈来学习做出决策。代理的目标是随时间最大化累积奖励。 RLHF通过用人类生成的反馈替换或补充预定义的奖励函数,从而允许模型更好地捕捉复杂的人类偏好和理解,从而增强了这个过程。
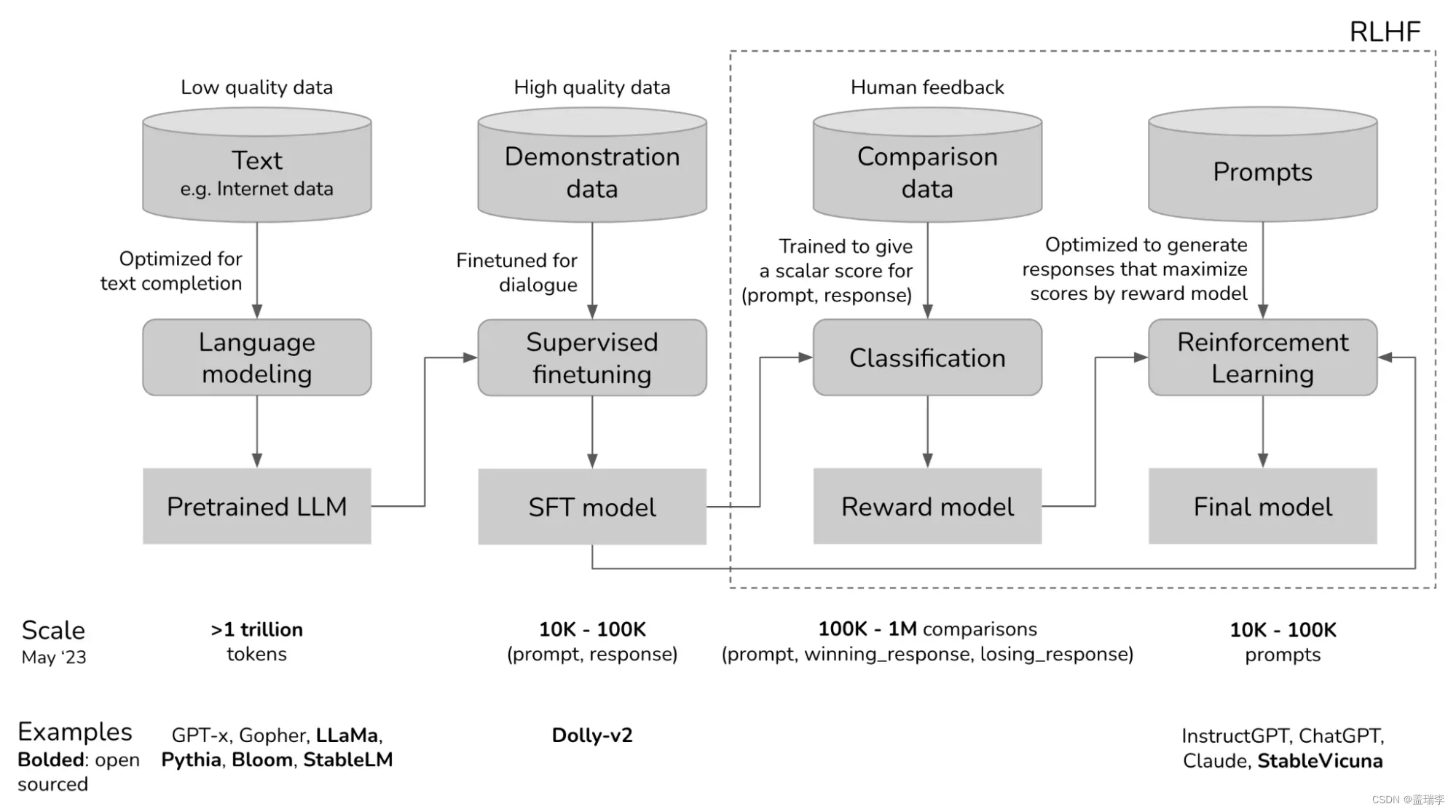
RLHF的过程可以分为几个步骤:
- 初始模型训练:一开始,AI模型使用监督学习进行训练,人类训练者提供正确行为的标记示例。模型学习根据给定的输入预测正确的动作或输出。
- 收集人类反馈:在初始模型被训练之后,人类训练者提供对模型表现的反馈。他们根据质量或正确性排名不同的模型生成的输出或行为。这些反馈被用来创建强化学习的奖励信号。
- 强化学习:然后使用Proximal Policy Optimization (PPO)或类似的算法对模型进行微调,这些算法将人类生成的奖励信号纳入其中。模型通过从人类训练者提供的反馈学习,不断提高其性能。
- 迭代过程:收集人类反馈并通过强化学习改进模型的过程是重复进行的,这导致模型的性能不断提高。
和gpt之间的关系
RLHF技术与GPT系列模型之间有密切的关系,因为RLHF被用于训练这些模型之一的ChatGPT,同时也被用于GPT-4的开发。这些模型使用大规模的神经网络,可以生成自然语言文本,例如对话和文章。
然而,对于自然语言处理任务,通常很难定义和测量奖励函数,特别是当涉及到人类价值和偏好的复杂任务时。在这种情况下,使用RLHF技术可以让语言模型在不需要人为指定奖励函数的情况下,通过与人类交互获得反馈信号来优化其生成的文本。这使得语言模型能够更好地捕捉人类的偏好和理解,并提供更加自然和准确的文本输出。因此,RLHF技术是GPT系列模型成功的关键之一,使其能够在许多自然语言处理任务中取得显著的成果。
reference:https://en.wikipedia.org/wiki/Reinforcement_learning_from_human_feedback
文章出处登录后可见!
已经登录?立即刷新