为视觉相似性构建强大的深度学习模型的 8 个技巧
3 个月浓缩的一般最佳实践,使您的连体网络表现良好并产生高质量的嵌入

不久前,我参加了在我以前的公司举行的数据科学挑战赛。目标是帮助海洋研究人员根据吸虫的外观更好地识别鲸鱼。
更具体地说,我们被要求为测试集的每个图像预测来自完整数据库(训练+测试)的前 20 个最相似的图像。
这不是一个标准的分类任务。
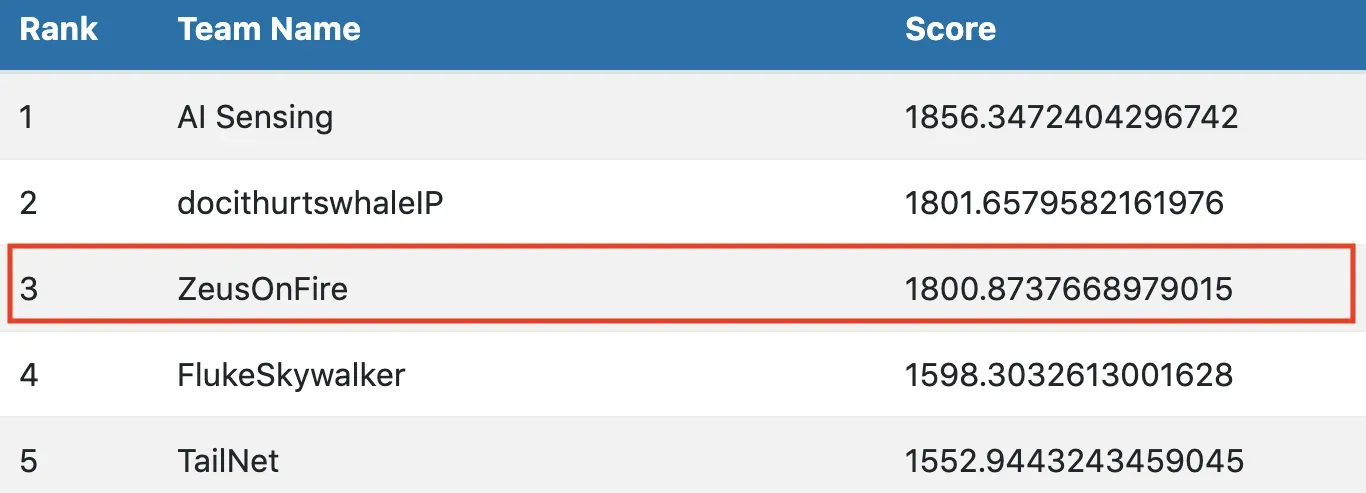
我花了 3 个月的时间进行原型设计,最终在最终(私人)排行榜上的 300 名参与者中排名第三。
对于这个故事,Zeus 是我的家用 GPU 驱动服务器。没错,它有名字。
但是,让我们不要讨论这个挑战的细节。
这篇文章的目的是与您分享我为视觉相似性任务构建强大的嵌入模型的技巧。这个挑战是一个极好的学习机会,我尝试了很多不同的技术。因此,我将在这里与您分享最有效的方法和无效的方法,并详细说明我在此过程中采取的不同步骤。
废话不多说,一起来看看吧🔍
PS:以下实验的代码在我的 Github repo 上。[0]
1 – 形式化问题并选择正确的损失?
我首先问自己的基本问题是:如何构建鲸鱼侥幸的数字表示,以有效嵌入其特征并用于相似性任务?
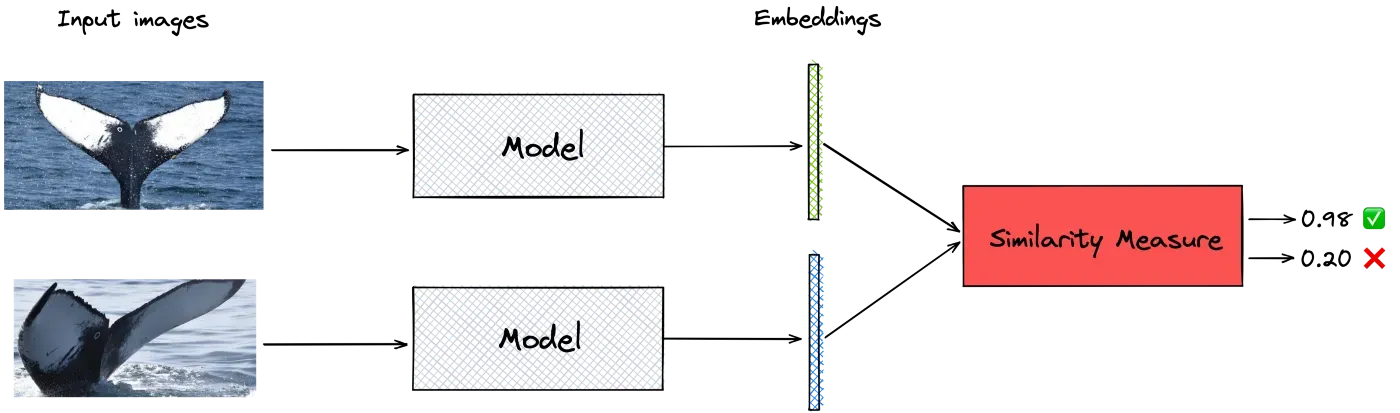
First approach: classification
我最初采用的天真的方法是训练一个卷积神经网络 (CNN),使用标准的 softmax 交叉熵损失对图像的标签集(鲸鱼 ID)进行分类,然后获取最后一个完全连接的输出层作为嵌入。不幸的是,训练网络以优化交叉熵并不能产生良好的相似性嵌入向量。
它在这个问题上效率不高的原因是交叉熵只学习如何将图像映射到标签,而不学习输入之间的相对距离(或相似性)。
当您需要嵌入视觉相似性任务时,您的网络应该在训练时明确学习如何在彼此之间比较和排列项目。如果你想了解更多,我推荐这篇文章。[0]
从分类到度量学习
学习有效嵌入以相互比较和排列输入的任务称为度量学习。
这是一个经过充分研究的主题,已在人脸识别或图像检索等流行应用中得到应用。
我不会在这篇文章中介绍什么是度量学习。有很好的教程在这里和这里很好地解释了它。[0][1][2]
我将只介绍我在这次挑战中尝试过的两个损失函数。
- Triplet loss
- ArcFace loss
1. Triplet Loss
Google 在 2015 年的 FaceNet 论文中引入了 Triplet loss。
作者通过设计一个系统来探索人脸嵌入的新技术,该系统学习从人脸图像到紧凑欧几里得空间的映射,其中距离直接对应于人脸相似度的度量。
所提出的方法优化了嵌入本身,而不是没有明确解决问题的中间损失。[0]
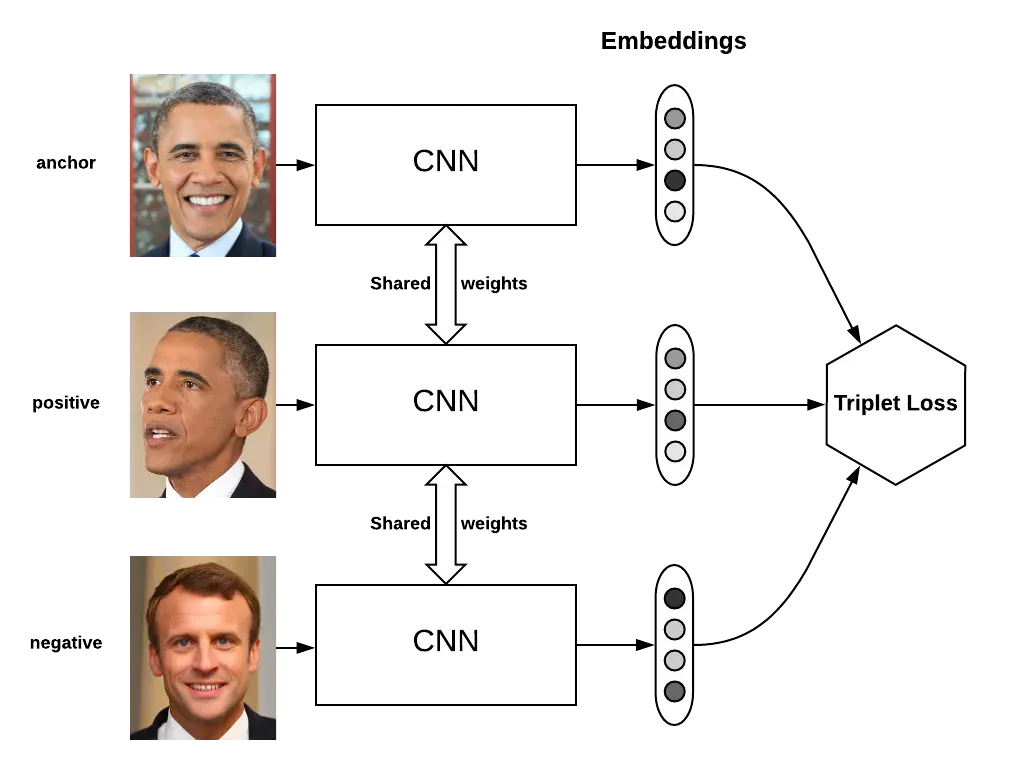
这种损失是在三组数据上定义的:
- 代表参考的锚点图像
- 与anchor同类别的正像
- 不同阶层的负面形象
并以这种方式优化模型的权重:
- 锚的嵌入和正图像的嵌入之间的欧式距离,即d(a, p),很低
- 锚的嵌入和负图像的嵌入之间的欧几里得距离,即d(a,n)很高
三元组损失可以形式化如下:
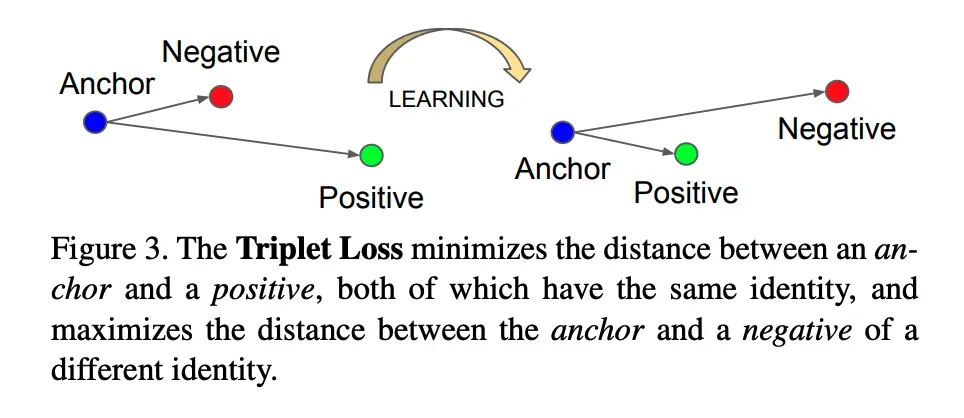
L = max(d(a, p) – d(a, n) + 边距, 0)
根据定义,这种损失的下限为 0。因此优化网络将使其尽可能接近 0。训练完成后:
- d(a, p) 变得非常小 ~0
- d(a, n) 大于 d(a, p) + 边距
我使用了一些训练技巧来改进三元组损失训练:
- 硬采样:我只使用硬三元组来优化损失。
一个硬三元组 (a, p, n) 满足这个不等式:d(a, n) < d(a, p) - PK 采样:我在 PyTorch 数据加载器中使用了一个采样器,以确保每个批次都是 PK 大小,由 P 个不同的类组成,每个类有 K 个图像。
- 三胞胎在线生成
你可以在我的 Github repo 上找到这些技巧的实现细节,如果你想了解更多关于这些技术的信息,我推荐阅读这篇论文。[0][1]
2. ArcFace
我在挑战结束前三周遇到了这种损失,我在尝试它的那一刻就被它的有效性所震撼。
ArcFace loss 已于 2019 年引入(CVPR),其主要目标是通过学习用于人脸识别的高度判别特征来最大化人脸类别的可分离性。根据论文作者的说法,这种方法在最常见的人脸识别基准上优于triplet loss、intra-loss和inter-loss。
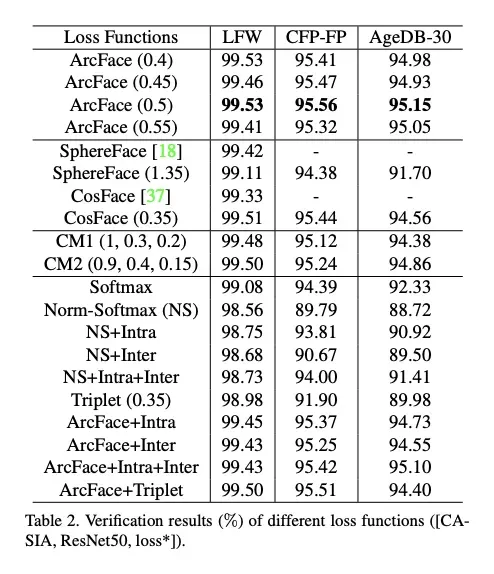
当给定从网络中提取的特征向量和相应的真实值(在本例中为鲸鱼 id)时,arcface 学习权重矩阵以将计算映射到新空间,在该空间中计算特征和目标之间的角度.因此,这个空间具有几何解释。
然后它为这个角度添加一个边距,恢复到原始空间,并应用交叉熵 softmax 损失。这种损失的主要好处是过渡到一个新的空间,在那里可分离性最大化。尽管进行了这种修改,但 ArcFace 与 softmax 交叉熵损失没有什么不同,因此训练开销很小。
当我尝试使用 ArcFace 时,我注意到三元组损失有一些好处:
- ArcFace 适用于大量类
- 它缓解了训练三元组损失时遇到的硬样本挖掘问题(因为它不需要一个)。它所需要的只是数据和相应的标签。
- 它提供了一个很好的几何解释
- 提供稳定的训练
- It converges faster
- 最重要的是,用这种损失训练的单个模型比用三重损失训练的五个模型的混合表现更好。
这就是我在最终提交中使用它的原因。
ArcFace 是我解决方案的基石。现在让我们来看看有助于有效地设置我的训练的不同步骤。
2 — 与数据合一🗂
这是不言而喻的,但我还是要说:花尽可能多的时间检查你的数据。无论您是从事计算机视觉还是 NLP 工作,深度学习模型,就像任何其他模型一样,都是垃圾进垃圾出。它有多少深层并不重要。如果你给它提供低质量的数据,你不应该希望得到好的结果。
我对这个挑战的数据做了几件事(这个过程显然适用于度量学习任务中的任何数据集):
- 我删除了分辨率非常低或根本看不到鲸鱼侥幸的嘈杂和损坏的图像
- 我丢弃了只有一个图像的类:这被证明是非常有效的。这背后的原因是度量学习任务需要一些关于每个类的上下文:每个类一张图像显然是不够的。
- 我提取了鲸鱼吸虫的边界框,以丢弃任何周围的噪音(水花、大海)并放大相关信息。这后来充当了注意力机制。
为此,我在 Piotr Skalski 构建的图像标记工具 makeense.ai 上注释了大约 300 条侥幸鲸后,从头开始训练了 Yolo-V3 Fluke 检测器。
我还使用这个优秀的 repo 来训练 Yolo-V3 模型。[0][1]
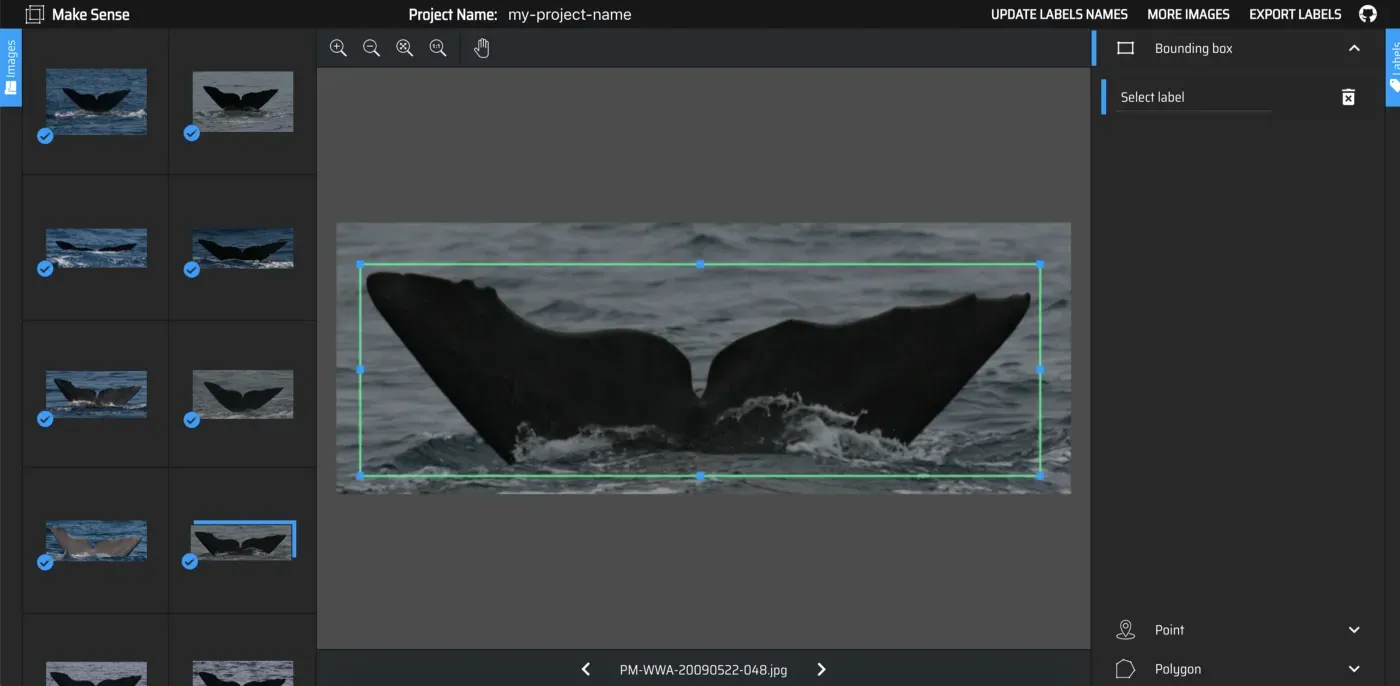
关键学习👨🏫:与复杂的建模相比,正确清理数据可能会赢得更多积分。
3 — 不要低估迁移学习的力量🔄
在比赛的前几周,我使用 ImageNet 预训练模型(renset34、densenet121 等)作为主干。很好,我的模型在一段时间后最终收敛了。
然后我查看了 Kaggle 座头鲸识别比赛数据。[0]
- 尽管有排行榜指标,但这场比赛与我们的挑战非常相似
- 数据具有与我们相同的结构,具有相同的类不平衡问题
- 侥幸看起来与我们的竞争对手不完全相同。它们来自另一个物种——但这很好。

我立即决定使用三元组损失对 ImageNet 预训练模型进行微调。
有趣的是事情的结果:
- 这产生了巨大的影响!我在排行榜上跳了起来
- 网络能够更快地收敛(减少 30% 的时期)
Key learnings 👨🏫:
- 迁移学习很少受到伤害。如果您从在 1000 个常见对象(动物、汽车等)上预训练的 ImageNet 模型开始,那么在您的类似数据集上预训练的网络更有可能更好。
- 迁移学习是一种为您的训练带来更多数据的间接方式
4 — 输入形状非常重要 📏📐 🔍
关于这项挑战的数据,有一个重要的细节需要提及:它的高分辨率。由于专业设备,一些图像达到 3000×1200 像素或更高。
当我开始比赛时,我将网络的输入大小设置为 224×224 像素,就像我通常在大多数图像分类问题中所做的那样。
然而,当我开始改变输入大小时,我的性能得到了提升。 480×480 是最适合我的输入形状。
Key learnings 👨🏫:
- 如果您正在处理高分辨率图像,请尝试增加网络的输入大小。 ImageNet 推荐的默认 224×224 输入形状并不总是最佳选择。使用较大的输入形状,您的网络可以学习区分一条鲸鱼与另一条鲸鱼的特定小细粒度细节。
- 更大并不总是更好。如果将输入形状增加到 1000px 左右,则更有可能遇到以下两个问题:
- 慢速训练:输入形状越高,你的网络参数越多,这显然需要更多的计算能力,并且由于过度拟合也不能保证收敛。
- 小图像性能不佳:当小图像上采样到 1000x1000px 分辨率时,原始信号已损坏。
5 — 复杂的架构不一定是最佳选择🤹
如果您对计算机视觉生态系统有点熟悉,您可能听说过一些流行的架构,例如 VGG 或 ResNet,或者不太可能听说过最近的复杂架构,例如 ResNet-Inception-V4 或 NASNet。
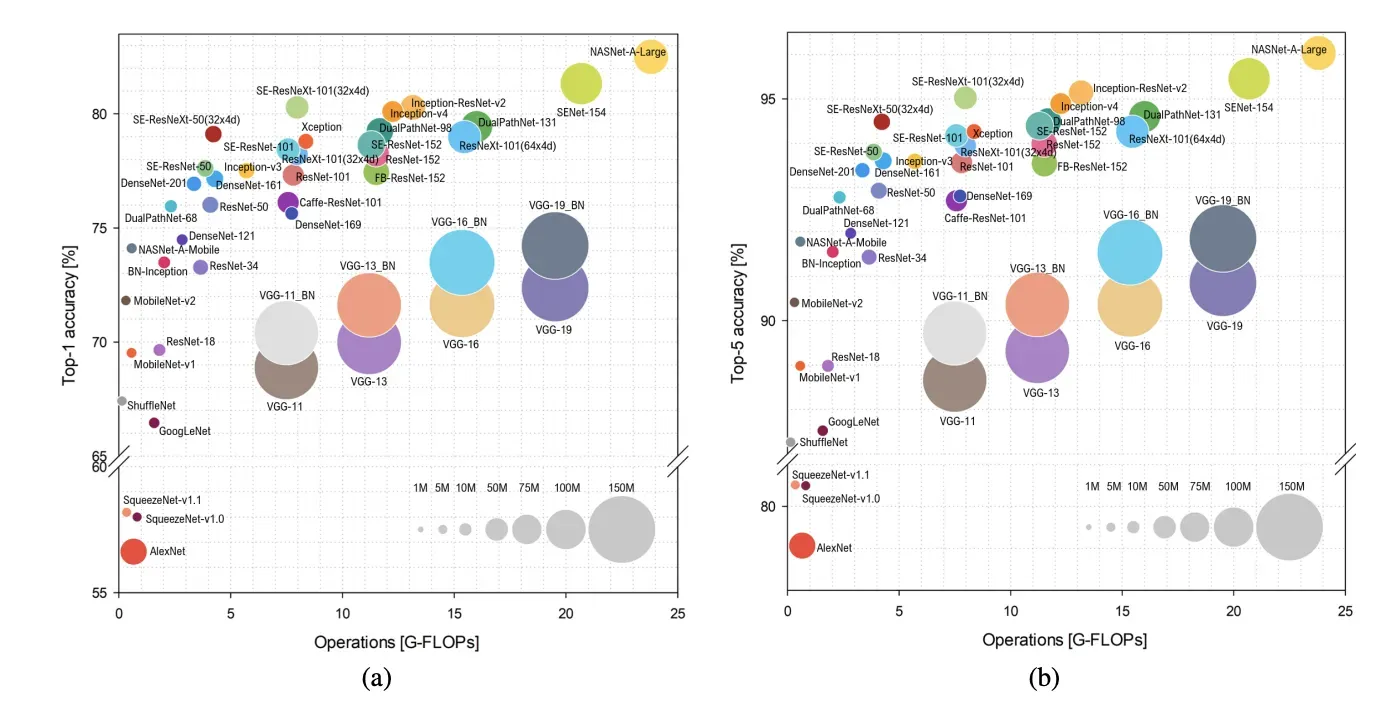
以下是我经过三个月的实验后得出的主要经验👨🏫:
- 大而深的最先进的骨干并不总是最佳选择:如果您的数据集很小(如本次挑战中的那个),它们很快就会过拟合,如果您的计算资源很少,您将无法训练他们
- 好的方法是从一个简单的网络开始,逐步增加复杂性,同时监控验证数据集的性能
- 如果您计划在 Web 应用程序中发布您的解决方案,您必须考虑模型大小、内存消耗、推理时间等。
6 — 设计稳健的管道 ⚙
我实施的培训流程包括 5 个主要步骤:
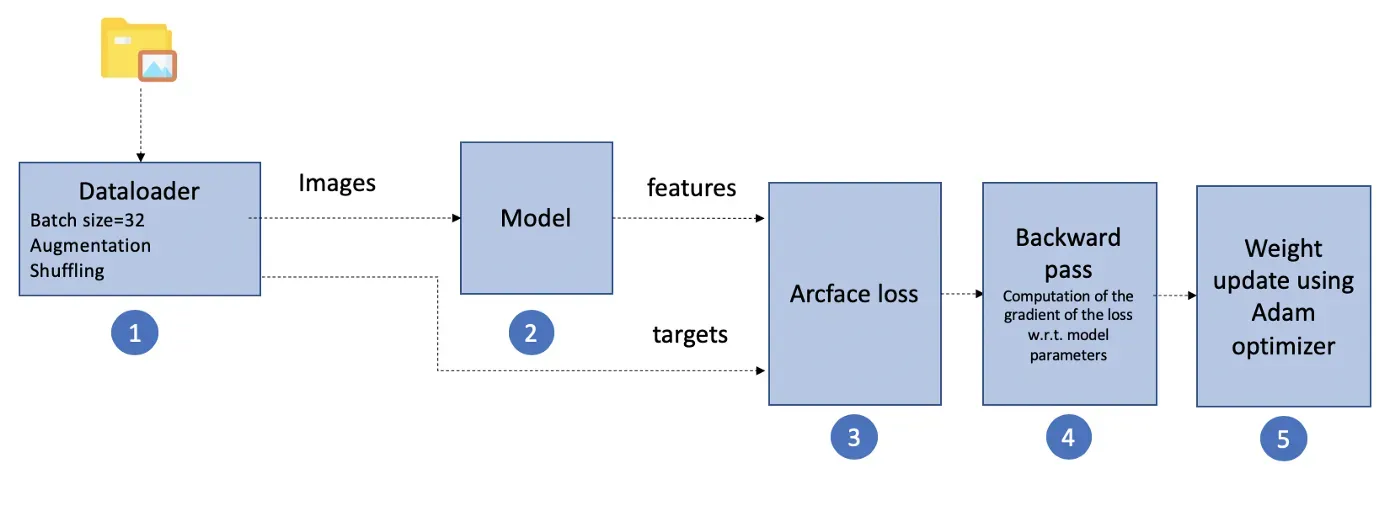
- 步骤 1:dataloder 连接到数据库并将图像和相应的标签分批提供给网络。它还负责在 epoch 之间打乱数据并应用动态数据增强。
重增强已被用作正则化效果,以实现更好的泛化。变换包括:高斯噪声和模糊、运动模糊、随机雨(模拟飞溅效果)、颜色偏移、亮度、色调和饱和度的随机变化、锐化、视角的随机变化、弹性变换、随机旋转 ± 20°、仿射变换(平移和剪切)和随机遮挡(增加泛化能力) - 第二步:前传。该模型将图像作为输入并生成特征。
- 第 3 步:计算特征和目标之间的弧面损失
- 第四步:反向传播。损失的梯度 w.r.t.计算模型参数
- 第 5 步:Adam 优化器使用损失的梯度更新权重。对每个批次执行此操作。
7 — 来自顶级 Kaggler 的一般训练技巧👨🏫
在这次比赛中,我做了很多实验。这是我的提示列表,可让训练安全、可重复且稳健。
- 固定种子以确保可重复性。您更有可能必须在脚本的开头编写这几行代码
import random
import numpy as np
import torch
random.seed(seed)
torch.manual_seed(0)
np.random.seed(0)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = FalseMore details here.[0]
- Adam 是一个安全的优化器。但是,您不应忘记将权重衰减设置为非零值。这充当正则化效果并防止损失波动。使用价值:1e-3
- 大量增强确实改善了结果。我从简单的旋转和平移开始,但是当我添加上面提到的变换时,我得到了更好的结果。增强缓解了数据缺乏的问题,提高了模型的稳定性和泛化性。为了构建一个有效的增强管道,我强烈推荐allementations 库。[0]
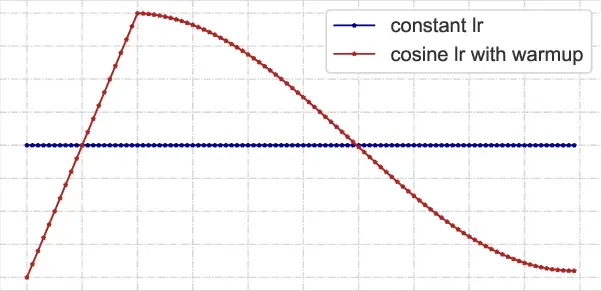
- 使用学习率调度程序在整个训练过程中降低学习率。这可以防止损失停留在局部最小值。
我最终选择的是一个预热调度器,然后是一个余弦退火。
它基本上从一个小的学习率开始,在几个时期(这称为预热阶段)达到目标(开始学习率),然后在余弦退火后降低它直到结束学习率。
预热阶段充当正则化效果,以防止早期过拟合。
- 在每个 epoch 结束时监控损失值和其他指标。我用 Tensorbaord 来绘制它。
- 伪标签可以给你一个优势:这种技术在 Kaggle 比赛中很常用。它包括在您的训练数据上训练一个模型,在测试数据上使用它来预测类别,采用最可信的预测(> 0.9 概率),将它们添加到原始训练数据中,然后再次重新训练。
- 确保您拥有正确的硬件。我可以访问具有 11Gb GPU 内存和 64GB RAM 的 GPU 服务器。在软件方面,我使用的是带有 PyTorch 1.1.0 和 torchvision 0.3.0 的 conda 虚拟环境。
在 480px 分辨率的图像上训练具有 ArcFace 损失的 Densenet121 主干每个 epoch 大约需要 1 分钟。收敛时间约为 90 个时期。 - 通过记录您的模型并在培训结束或期间保存它们来跟踪您的体验。你会在我的 Github 存储库中找到这是如何完成的。[0]
8 — 分而治之:结合多个模型进行最终提交 ⚡
我使用前面的管道和以下参数训练了两个模型:
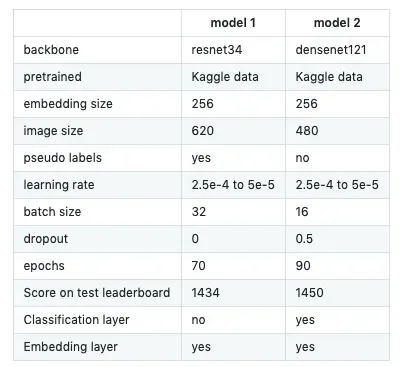
让我在最终得分中占据优势的是我将它们组合在一起的方式。这是一种简单的元嵌入技术,在自然语言处理中非常常用。
它包括在所有样本上生成每个模型的嵌入,然后将它们连接起来。
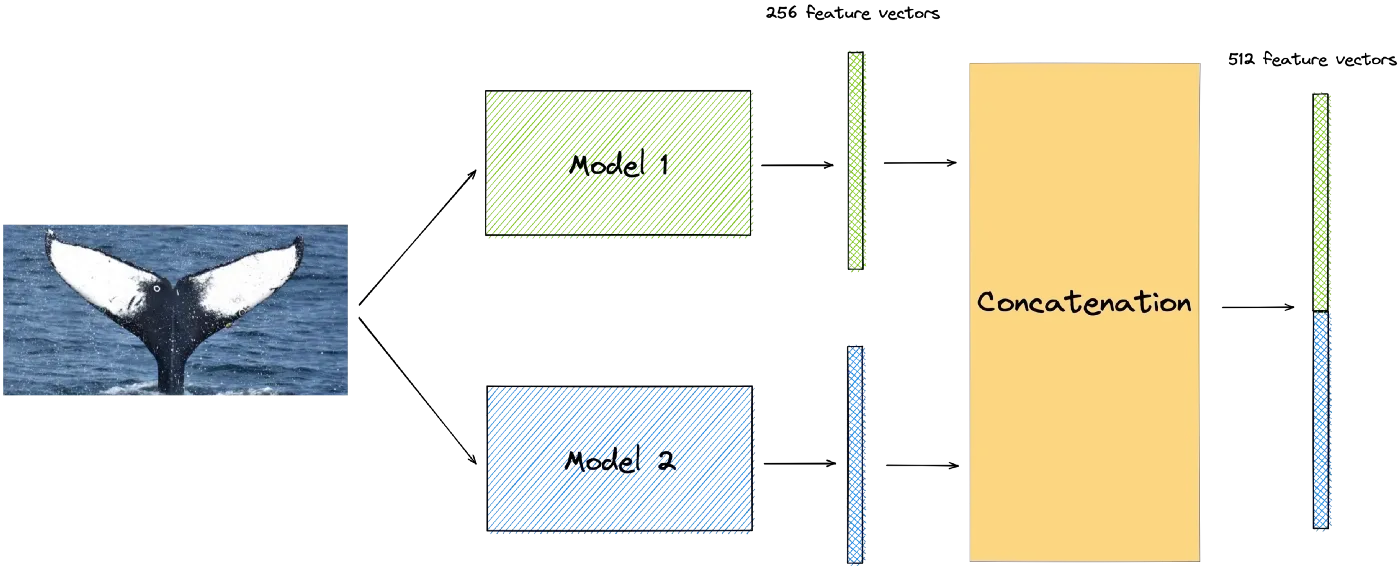
此方法用于生成训练和测试数据集的元嵌入。然后,使用相同的计算来生成提交。
Key learning 👨🏫:
- 当基本模型在主干架构(resnet34 vsdensenet121)、图像输入大小(480 vs 620)、正则化方案(dropout vs no dropout)中不同时,元嵌入连接技术提供了一种有趣的嵌入
- 每个单独的基础模型“看到”不同的东西:结合它们的嵌入会产生一个新的混合模型,具有增强的表示能力。
Final words 🙏
我要感谢整个 GDSC 团队为使这一挑战成为一个很好的学习机会所做的工作,感谢 Lisa Steiner 让我们有机会将我们的知识应用到一个新领域。
我希望你能在这里找到可用于其他计算机视觉和深度学习项目的资源。
References 📜
- 面网:https://arxiv.org/pdf/1503.03832.pdf[0]
- 为人员重新识别的三重损失辩护:https://arxiv.org/pdf/1703.07737.pdf[0]
- Ranking Loss、Contrastive Loss、Margin Loss、Triplet Loss、Hinge Loss:https://gombru.github.io/2019/04/03/ranking_loss/[0]
- 三重损失:https://omoindrot.github.io/triplet-loss[0]
- ArcFace 论文:https://arxiv.org/pdf/1801.07698.pdf[0]
- 解释 ArcFace 损失:https://medium.com/1-minute-papers/arcface-additive-angular-margin-loss-for-deep-face-recognition-d02297605f8d[0]
新媒体?您可以以每月 5 美元的价格订阅并解锁关于各种主题(技术、设计、创业……)的无限文章。您可以通过单击我的推荐链接来支持我[0]

文章出处登录后可见!