目录
1–nn.Embedding()的用法
import torch.nn as nn
embedding = nn.Embedding(num_embeddings = 10, embedding_dim = 256)nn.Embedding()产生一个权重矩阵weight,其shape为(num_embeddings, embedding_dim),表示生成num_embeddings个具有embedding_dim大小的嵌入向量;
输入input的形状shape为(batch_size, Seq_len),batch_size表示样本数(NLP句子数),Seq_len表示序列的长度(每个句子单词个数);
nn.Embedding(input)的输出output具有(batch_size,Seq_len,embedding_dim)的形状大小;
2–实例展示:
① 代码:
import torch
import torch.nn as nn
if __name__ == "__main__":
input = torch.randint(low = 0, high = 5, size = (2, 9))
input = torch.LongTensor(input)
embedding = nn.Embedding(num_embeddings=6, embedding_dim = 3)
output = embedding(input)
print("input.shape:", input.shape) # (2, 9) 2个句子,9个单词
print("embedding.shape:", embedding.weight.shape) # (6, 3)
print("output.shape", output.shape) # (2, 9, 3) 2个句子,9个单词,每个单词用一个3维的向量表示
print("input:", input)
print("embedding:", embedding.weight)
print("output:", output)
print("All Done !")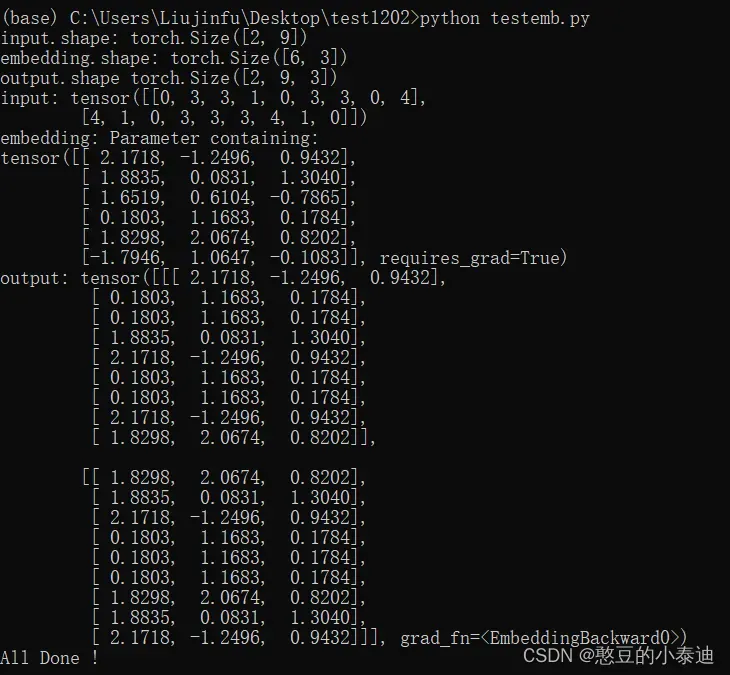
② 分析:
output = embedding(input) 的作用是将每个单词用一个 embedding_dim 大小的向量进行表示,所以对于一个(batch_size,Seq_len)的输入input来说,其输出 output 是一个(batch_size,Seq_len,embedding_dim)大小的 tensor。
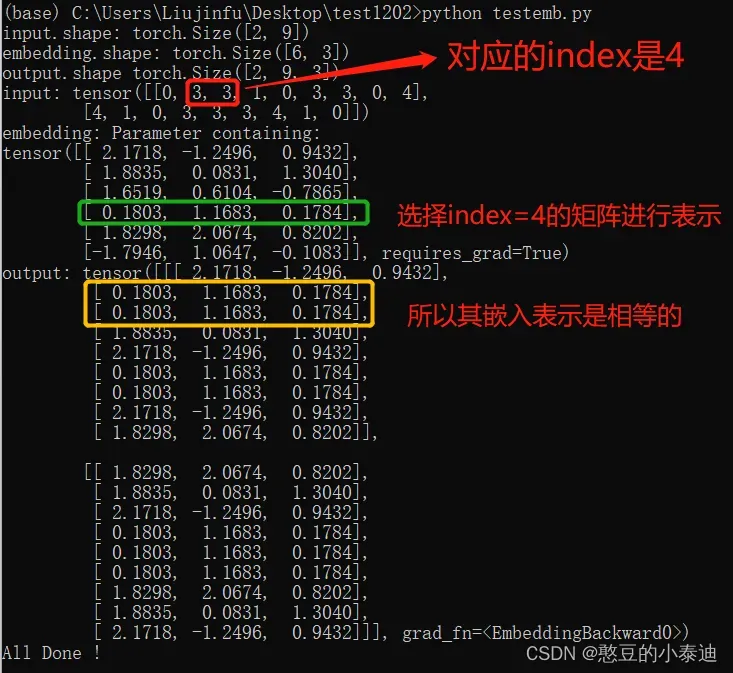
在选择 embedding_dim 大小的向量进行表示时,是根据每个单词的数据进行选择;例如在下图中,第一个句子中两个单词的数据表示均为 3(红框表示),则对应的index均为 4,都要选择embedding.weight 中 index 为 4(绿框表示)的嵌入向量进行表示,所以在最终的 output 中两个单词的嵌入向量是相同的(黄框表示)。
3–注意的问题
① nn.Embedding() 的输入必须是 LongTensor 类型的张量;
② 在input输入中,数据大小(极差)不能超过 nn.Embedding() 初始化中 num_embeddings 的大小,即数据对应的 index 不能大于 num_embeddings;
文章出处登录后可见!